Help us to develop the latest tools to promote transparency in VCM — read on to find out how!

When we first began to explore data on the voluntary carbon market, we quickly realized that there was a need for aggregation, synthesis, and standardization across projects and registries.
Starting with the largest registries first, we’ve brought together data on nearly 19,000 projects and over 250,000 retirement transactions, as well as news, quality ratings, pricing, and brokers.
We also quickly saw that a lot of the value-additive data was hidden away in project design documents (PDDs). From self-reported data on risk assessments, which determines projects’ buffer pool, to data on CO2 issuances over the projects’ lifecycles, a lot of valuable data is stored in the documents associated with each project.
We’re excited to announce that we’ve turned the unstructured data hidden in PDDs into searchable and actionable information that can help users better understand the voluntary carbon market.
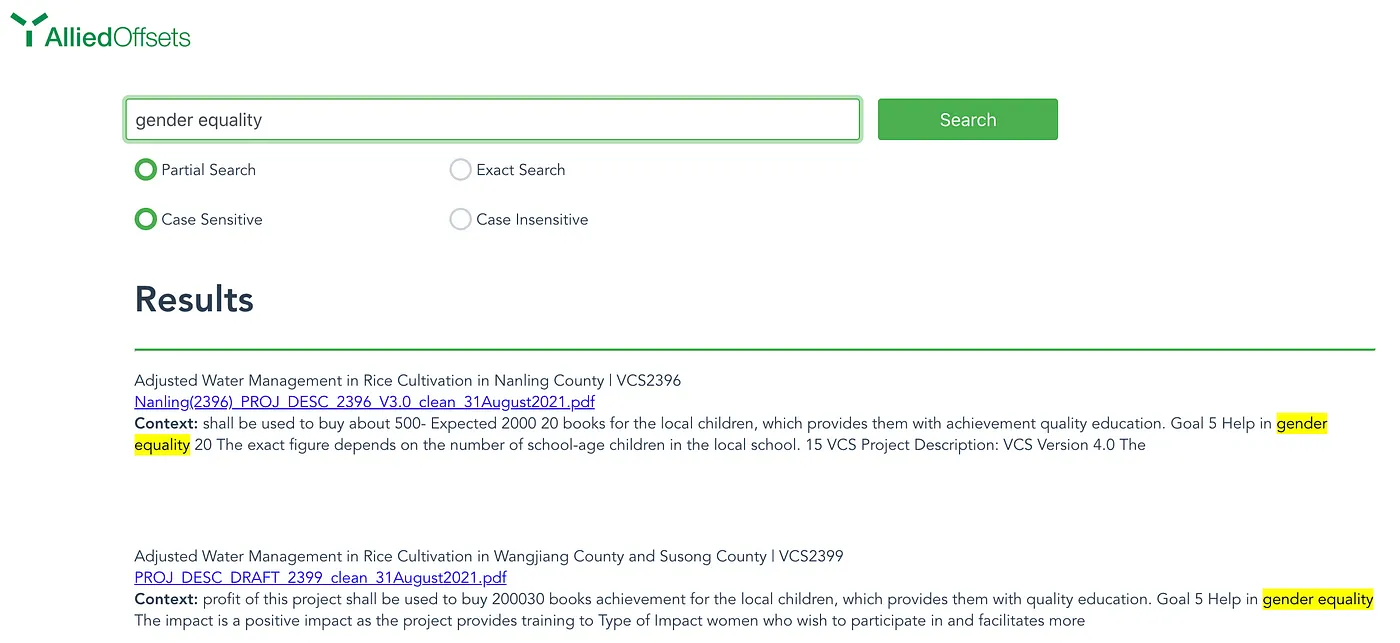
Step one in the process has been to digitize all of the PDDs for Verra projects, in order to make them searchable. This means being able to search across all PDDs to find keywords, phrases, and data points that are important to your use case.
There are myriad use cases for this functionality, including:
- Identifying specific tree types or animal species that are on the project’s land area
- Finding companies or individuals involved with specific projects
- Getting contact information for individuals involved with a project
- Identifying co-benefits or SDGs that may be promoted by a project
- Locating which companies or individuals are based in a certain city
- Understanding which technologies (e.g., wind turbines, or monitoring equipment) are used by projects
- Highlighting projects with methodology-specific jargon (e.g., biomass expansion factor)
In other words, it allows users to filter projects in a completely novel way and helps them find the needle in the haystack they are looking for.
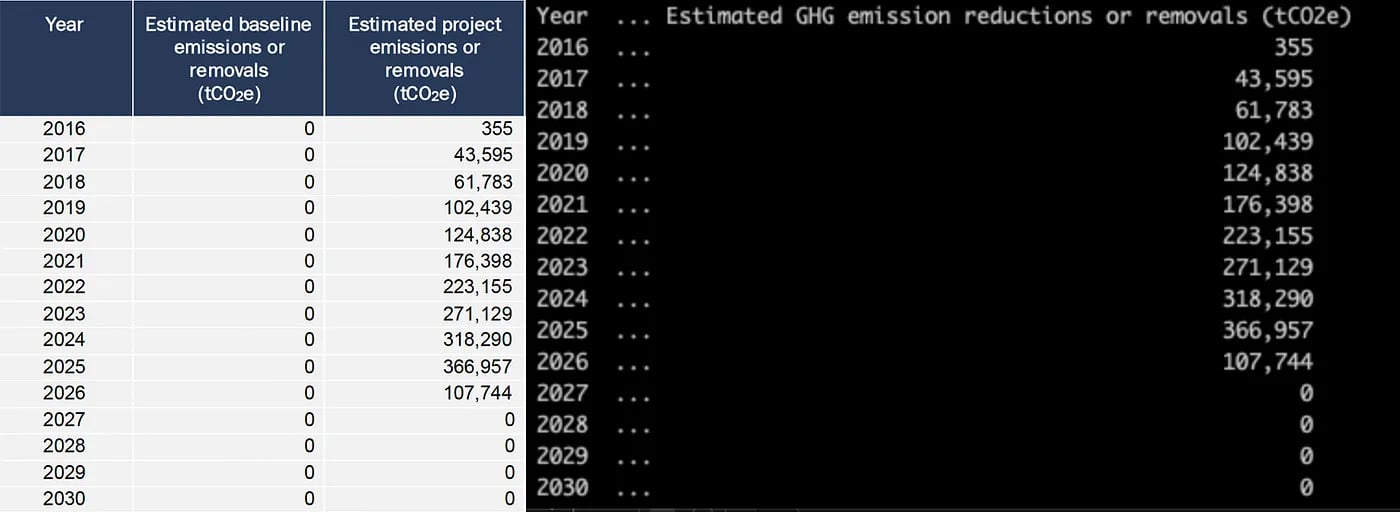
As a next step, we are going through more structured data like tables, in order to pull out a wealth of data that can be highly useful to researchers, project developers, and buyers of credits. This include information like:
- Annual carbon credit issuance numbers over the course of the project lifecycle
- The makeup of a project’s soil composition
- Risk reporting information that determines its buffer pool
- Stakeholder consultation feedback
- And much more!
In order to help us create the best product around this, we’re looking for users to test out both the text search and table data extraction. We’ve already reached out to some of our clients, who have provided invaluable feedback, and it’d be great to have the wider market’s view on the most useful features and functionality.
If you’re interested in getting access to the tool, please message hello@alliedoffsets.com!