Introduction
Outliers, those intriguing islands of peculiarity in vast seas of data, play a pivotal role in data analysis. They represent data points that deviate significantly from the majority, holding valuable insights into unexpected patterns, errors, rare events, or hidden information.
From e-commerce platforms combatting fraudulent activities to manufacturers ensuring product quality, outlier detection has become indispensable in the era of data-driven decision-making. These exceptional data points can distort statistical analyses, impact machine learning models, and lead to erroneous conclusions.
Detecting outliers has diverse applications across various industries, including fraud detection, network monitoring, quality control, and healthcare anomaly detection. Moreover, outliers often hold unique gems of valuable insights that can redefine our understanding of complex phenomena.
In this blog, we embark on a comprehensive journey into the realm of outlier detection. We will explore the underlying concepts, understand the significance of detecting outliers, and delve into various methods to identify these exceptional data points. By the end of this exploration, you’ll be equipped with a versatile toolkit to unveil the mysteries hidden within your datasets and make well-informed decisions.
Join us as we navigate the exciting world of outlier detection, shedding light on the unexpected in the data landscape. From the Z-score, IQR, to the Isolation Forest, this data adventure awaits with valuable discoveries that can revolutionize your data analysis endeavours. Let’s dive in and unlock the secrets of outliers!
Why Outlier Detection Matters
Outliers can distort statistical analyses, impact machine learning models, and lead to incorrect conclusions. They might represent errors, rare events, or even valuable hidden information. Identifying outliers is essential because it allows us to:
- Improve Data Quality: By identifying and handling outliers, data quality can be enhanced, leading to more accurate analyses and predictions.
- Improve Model Performance: Removing outliers or treating them differently in machine learning models can improve model performance and generalization.
- Discover Anomalous Patterns: Outliers can provide insights into rare events or unusual behaviours that might be critical for businesses or research.
Methods of Outlier Detection
There are several methods to detect outliers. We will discuss three common approaches: Z-score, IQR (Interquartile Range), and Isolation Forest.
Z-Score Method
The Z-score measures how many standard deviations a data point is away from the mean. Any data point with a Z-score greater than a certain threshold is considered an outlier.
Z-score formula: Z=(X−μ)/σ
where:
X = data point,
μ = mean of the data
σ = standard deviation of the data
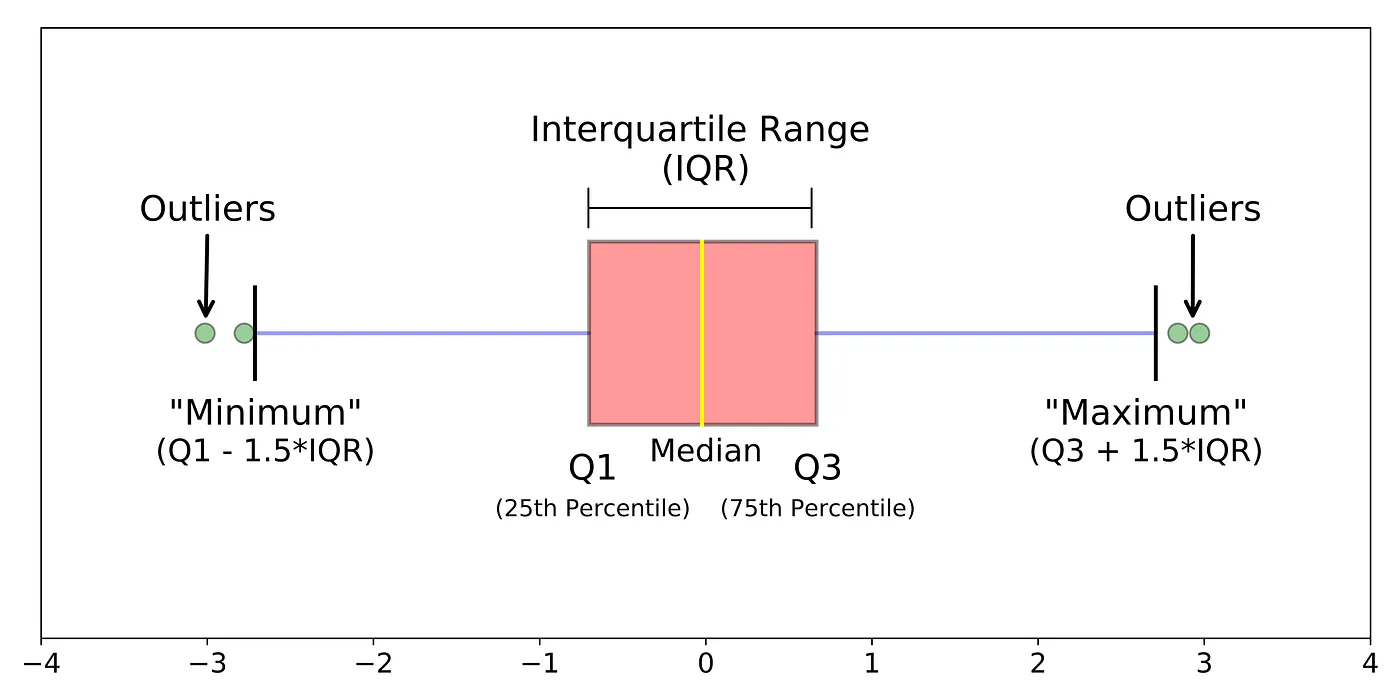
IQR (Interquartile Range) Method
The IQR method relies on the range between the first quartile (Q1) and the third quartile (Q3). Data points beyond a certain threshold from the IQR are considered outliers.
IQR formula: IQR=Q3−Q1
Outliers are points outside the range: [Q1−1.5∗IQR, Q3+1.5∗IQR].
Isolation Forest
The Isolation Forest algorithm is based on the principle that outliers are easier to isolate and identify. It constructs isolation trees by randomly selecting features and splitting data points until each point is isolated or grouped with a small number of other points. Outliers will be isolated early, making them easier to detect.
Dummy Data Example and Code:
Let’s create a dummy dataset to demonstrate outlier detection using Python:
import numpy as np
import pandas as pd
# Create a dummy dataset with outliers
np.random.seed(42)
data = np.concatenate([np.random.normal(0, 1, 50), np.array([10, -10])])
df = pd.DataFrame(data, columns=["Value"])
# Visualization
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 5))
sns.boxplot(data=df, x="Value")
plt.title("Boxplot of Dummy Data")
plt.show()
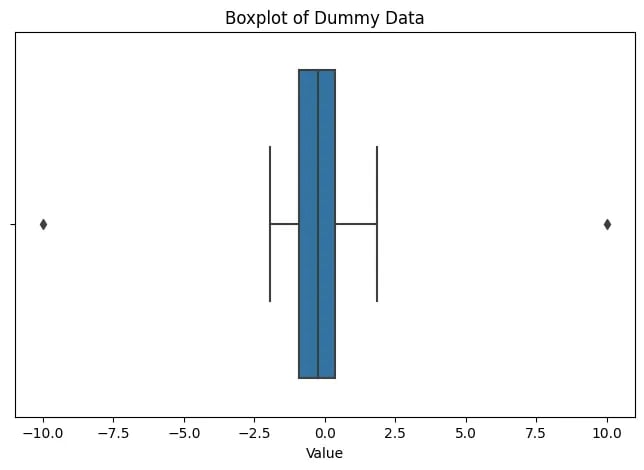
In this dummy dataset, we added two outliers (10 and -10) to a normally distributed dataset.
Outlier Detection Code
Z-Score Method
from scipy import stats
def detect_outliers_zscore(data, threshold=3):
z_scores = np.abs(stats.zscore(data))
return np.where(z_scores > threshold)
outliers_zscore = detect_outliers_zscore(df["Value"])
print("Outliers detected using Z-Score method:", df.iloc[outliers_zscore])
IQR (Interquartile Range) Method
def detect_outliers_iqr(data):
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
return data[(data < Q1 - 1.5 * IQR) | (data > Q3 + 1.5 * IQR)]
outliers_iqr = detect_outliers_iqr(df["Value"])
print("Outliers detected using IQR method:", outliers_iqr)
Isolation Forest
from sklearn.ensemble import IsolationForest
isolation_forest = IsolationForest(contamination=0.1)
isolation_forest.fit(df[["Value"]])
df["Outlier"] = isolation_forest.predict(df[["Value"]])
outliers_isolation = df[df["Outlier"] == -1]
print("Outliers detected using Isolation Forest:", outliers_isolation)
Outlier Removal
Removing outliers is a critical step in outlier detection, but it requires careful consideration. Outliers should be removed only when they are genuinely erroneous or when their presence significantly affects the data quality and model performance. Here’s an example of how outliers can be removed using the Z-score method and when it might be appropriate to remove them:
import numpy as np
import pandas as pd
from scipy import stats
import seaborn as sns
import matplotlib.pyplot as plt
# Create a dummy dataset with outliers
np.random.seed(42)
data = np.concatenate([np.random.normal(0, 1, 50), np.array([10, -10])])
df = pd.DataFrame(data, columns=["Value"])
# Function to remove outliers using Z-score method
def remove_outliers_zscore(data, threshold=3):
z_scores = np.abs(stats.zscore(data))
outliers_indices = np.where(z_scores > threshold)
return data.drop(data.index[outliers_indices])
# Visualization - Boxplot of the original dataset with outliers
plt.figure(figsize=(10, 6))
plt.subplot(1, 2, 1)
sns.boxplot(data=df, x="Value")
plt.title("Original Dataset (with Outliers)")
plt.xlabel("Value")
plt.ylabel("")
# Removing outliers using Z-score method (threshold=3)
df_no_outliers = remove_outliers_zscore(df["Value"])
# Convert Series to DataFrame for visualization
df_no_outliers = pd.DataFrame(df_no_outliers, columns=["Value"])
# Visualization - Boxplot of the dataset without outliers
plt.subplot(1, 2, 2)
sns.boxplot(data=df_no_outliers, x="Value")
plt.title("Dataset without Outliers")
plt.xlabel("Value")
plt.ylabel("")
plt.tight_layout()
plt.show()
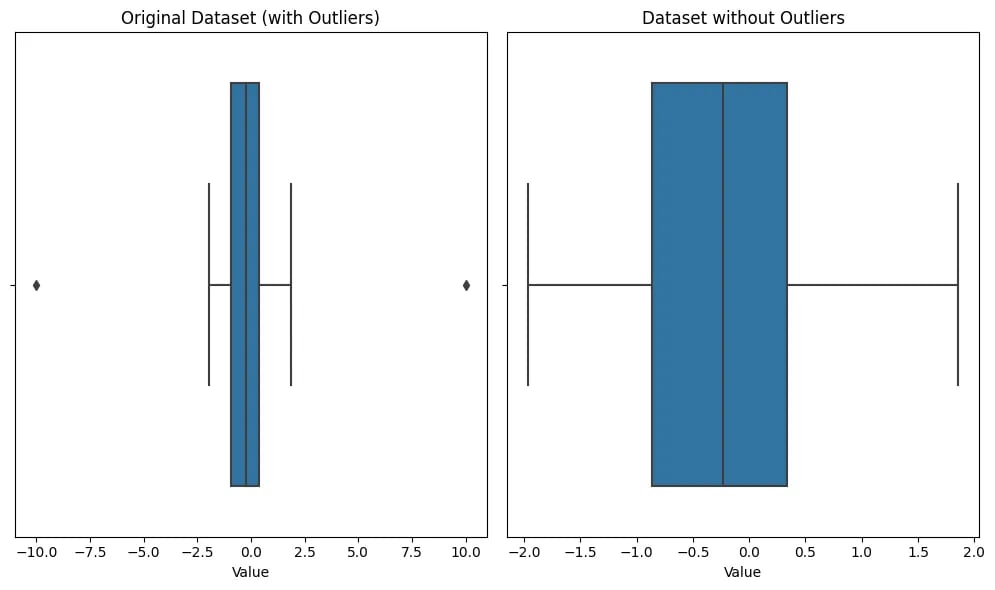
The code will generate two side-by-side boxplots. The left plot shows the original dataset with outliers, and the right plot shows the dataset after removing outliers using the Z-score method.
By visualizing the boxplots, you can observe how the outliers influenced the data distribution and how their removal affected the overall distribution of the data. This visualization can help you assess the impact of outlier removal on your data and make informed decisions regarding the handling of outliers in your analysis.
When to remove outliers
- Data Errors: If outliers are the result of data entry errors or measurement mistakes, they should be removed to ensure data accuracy.
- Model Performance: In machine learning, outliers can have a significant impact on model training and prediction. If outliers are causing the model to perform poorly, removing them might be necessary to improve model accuracy and generalization.
- Data Distribution: If the dataset follows a specific distribution, and outliers disrupt this distribution, their removal might be necessary to maintain the integrity of the data distribution.
- Context and Domain Knowledge: Consider the context of the data and your domain knowledge. If you are confident that the outliers represent genuine anomalies or errors, removing them can lead to more reliable results.
However, it’s essential to exercise caution and avoid removing outliers blindly, as this could lead to the loss of valuable information. Outliers might also represent rare events or critical patterns, which, if removed, could compromise the accuracy of analyses and predictions. Always analyze the impact of removing outliers on your specific use case before making a decision. When in doubt, consult with domain experts to ensure that outlier removal aligns with the overall goals of the analysis.
Advantages and Disadvantages of Outlier Detection
Advantages
- Data Quality Improvement: Outlier detection helps identify data errors and ensures data integrity.
- Better Model Performance: Eliminating or treating outliers can improve model performance and accuracy.
- Anomaly Discovery: Outliers often represent unique events or behaviours, providing valuable insights.
Disadvantages
- Subjectivity: Setting appropriate outlier detection thresholds can be subjective and impact the results.
- Data Loss: Overzealous outlier removal can result in the loss of valuable information.
- Algorithm Sensitivity: Different outlier detection algorithms may produce varying results, leading to uncertainty in outlier identification.
Conclusion
In conclusion, outlier detection serves as a fundamental pillar of data analysis, offering valuable insights into unexpected patterns, errors, and rare events. By identifying and handling outliers effectively, we can enhance data quality, improve model performance, and gain unique perspectives on our datasets.
Throughout this exploration, we’ve discussed various methods, from Z-score and IQR to Isolation Forest, each with its strengths and limitations. Remember, the key lies in striking a balance between outlier removal and retaining essential information, leveraging domain knowledge to make informed decisions.
As you embark on your data analysis journey, embrace the outliers as beacons of hidden knowledge, waiting to reveal untold stories. By honing your outlier detection skills, you will navigate the seas of data with confidence, uncovering valuable insights that shape a brighter future.
May your quest for outliers lead you to new discoveries and illuminate the path to data-driven success. With outliers as your guide, may you embark on limitless possibilities in the realm of data analysis. Happy exploring!